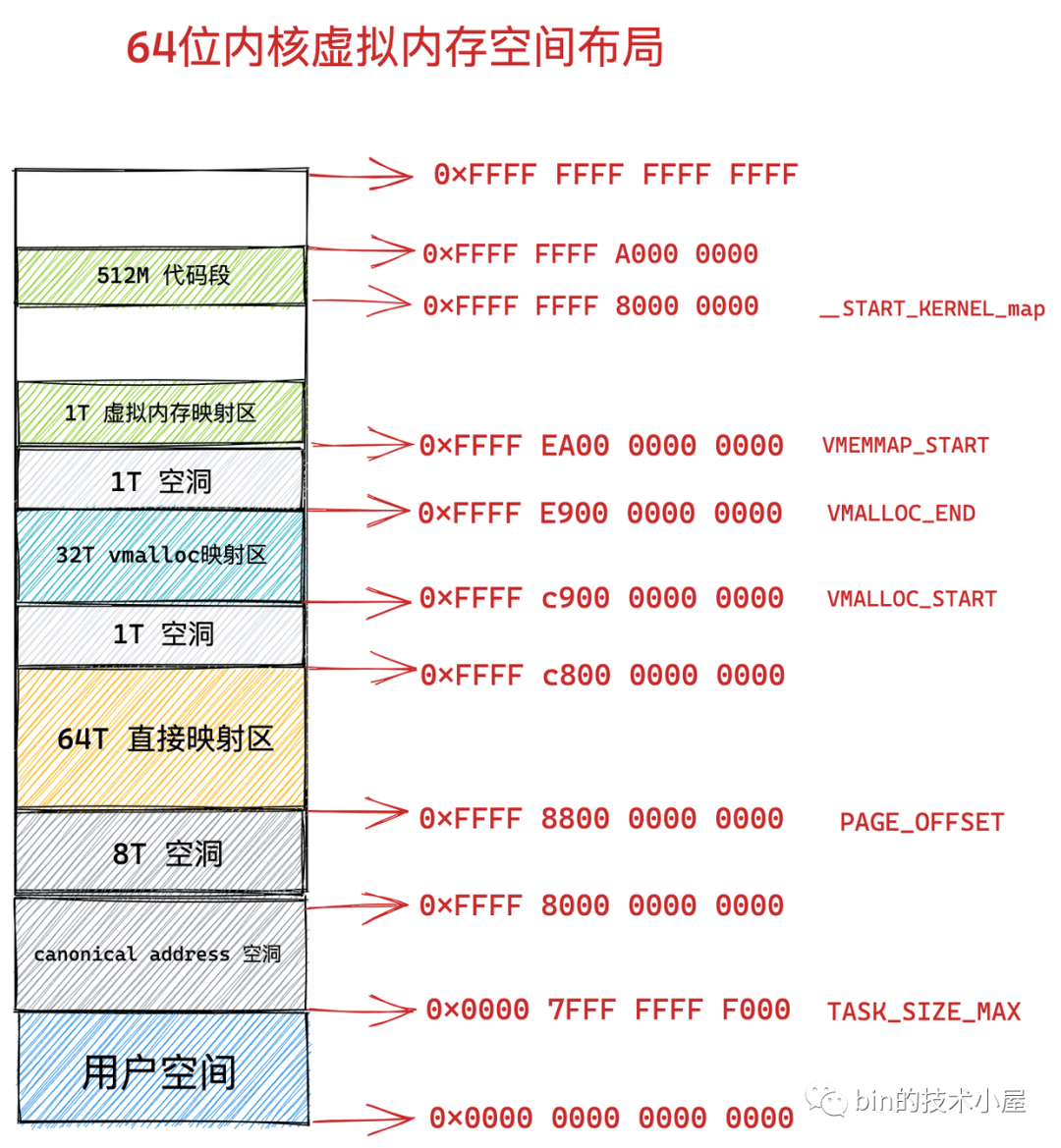
// arch/x86/mm/fault.c staticvoidsanitize_error_code(unsignedlong address, unsignedlong *error_code) { /* * To avoid leaking information about the kernel page * table layout, pretend that user-mode accesses to * kernel addresses are always protection faults. * * NB: This means that failed vsyscalls with vsyscall=none * will have the PROT bit. This doesn't leak any * information and does not appear to cause any problems. */ if (address >= TASK_SIZE_MAX) <-----检查访问的地址是否大于最大进程虚拟地址空间 *error_code |= X86_PF_PROT; }
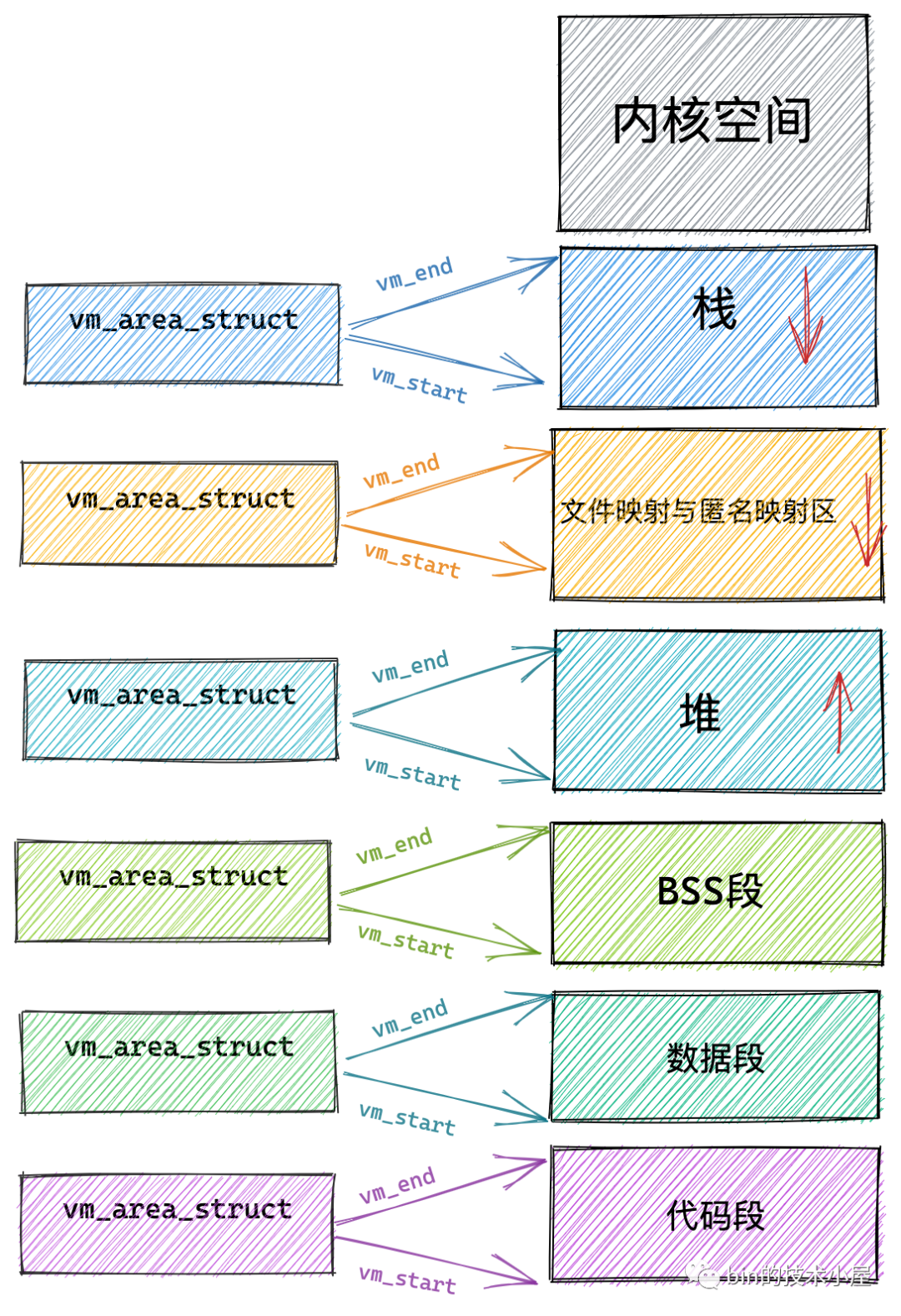
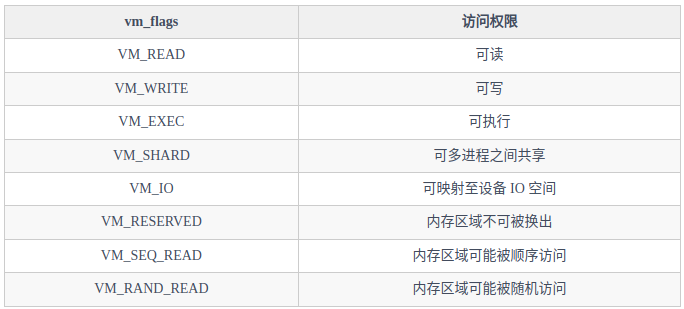
unsignedlong vm_start; /* Our start address within vm_mm. */ unsignedlong vm_end; /* The first byte after our end address within vm_mm. */ <-----描述的是 [vm_start,vm_end) 这样一段左闭右开的虚拟内存区域 /* * Access permissions of this VMA. */ pgprot_t vm_page_prot; unsignedlong vm_flags; structmm_struct *vm_mm;
structanon_vma *anon_vma;/* Serialized by page_table_lock */ structfile * vm_file;/* File we map to (can be NULL). */ unsignedlong vm_pgoff; /* Offset (within vm_file) in PAGE_SIZE units */ void * vm_private_data; /* was vm_pte (shared mem) */ /* Function pointers to deal with this struct. */ conststructvm_operations_struct *vm_ops; }
./include/linux/mm.h /* * These are the virtual MM functions - opening of an area, closing and * unmapping it (needed to keep files on disk up-to-date etc), pointer * to the functions called when a no-page or a wp-page exception occurs. */ structvm_operations_struct { void (*open)(struct vm_area_struct * area); /** * @close: Called when the VMA is being removed from the MM. * Context: User context. May sleep. Caller holds mmap_lock. */ void (*close)(struct vm_area_struct * area); /* Called any time before splitting to check if it's allowed */ int (*may_split)(struct vm_area_struct *area, unsignedlong addr); int (*mremap)(struct vm_area_struct *area); /* * Called by mprotect() to make driver-specific permission * checks before mprotect() is finalised. The VMA must not * be modified. Returns 0 if mprotect() can proceed. */ int (*mprotect)(struct vm_area_struct *vma, unsignedlong start, unsignedlong end, unsignedlong newflags); vm_fault_t (*fault)(struct vm_fault *vmf); vm_fault_t (*huge_fault)(struct vm_fault *vmf, unsignedint order); vm_fault_t (*map_pages)(struct vm_fault *vmf, pgoff_t start_pgoff, pgoff_t end_pgoff); unsignedlong(*pagesize)(struct vm_area_struct * area);
/* notification that a previously read-only page is about to become * writable, if an error is returned it will cause a SIGBUS */ vm_fault_t (*page_mkwrite)(struct vm_fault *vmf);
/* same as page_mkwrite when using VM_PFNMAP|VM_MIXEDMAP */ vm_fault_t (*pfn_mkwrite)(struct vm_fault *vmf);
/* called by access_process_vm when get_user_pages() fails, typically * for use by special VMAs. See also generic_access_phys() for a generic * implementation useful for any iomem mapping. */ int (*access)(struct vm_area_struct *vma, unsignedlong addr, void *buf, int len, int write);
/* Called by the /proc/PID/maps code to ask the vma whether it * has a special name. Returning non-NULL will also cause this * vma to be dumped unconditionally. */ constchar *(*name)(struct vm_area_struct *vma);
#ifdef CONFIG_NUMA /* * set_policy() op must add a reference to any non-NULL @new mempolicy * to hold the policy upon return. Caller should pass NULL @new to * remove a policy and fall back to surrounding context--i.e. do not * install a MPOL_DEFAULT policy, nor the task or system default * mempolicy. */ int (*set_policy)(struct vm_area_struct *vma, struct mempolicy *new);
/* * get_policy() op must add reference [mpol_get()] to any policy at * (vma,addr) marked as MPOL_SHARED. The shared policy infrastructure * in mm/mempolicy.c will do this automatically. * get_policy() must NOT add a ref if the policy at (vma,addr) is not * marked as MPOL_SHARED. vma policies are protected by the mmap_lock. * If no [shared/vma] mempolicy exists at the addr, get_policy() op * must return NULL--i.e., do not "fallback" to task or system default * policy. */ structmempolicy *(*get_policy)(structvm_area_struct *vma, unsignedlongaddr, pgoff_t *ilx); #endif /* * Called by vm_normal_page() for special PTEs to find the * page for @addr. This is useful if the default behavior * (using pte_page()) would not find the correct page. */ structpage *(*find_special_page)(structvm_area_struct *vma, unsignedlongaddr); };